show commands
Router
1 | show running-config |
Switch
1 | show ip interface brief |
CLI Passwords, Generic Commands - 4
Enable password for privilege EXEC mode
1 | //case-sensitive password; enable for prev EXEC mode; visible in running-conf |
Copy configurations from RAM to NVRAM
1 | Router(config)#write |
Enable password-encryption
1 | //Command will encrypt passwords such that its obscured in running-config; Uses CISCO Type 7 |
Ethernet LAN Switching - 6
Show MAC address table
1 | SW1#show mac address-table |
Clear MAC addresses
1 | //Clears all dynamic MAC addresses |
IPv4 Addressing (Assigning IPv4 Addresses)
Show command for each interface; routers are administratively down by default
1 | //Status = layer 1 (physical) ; Protocol = layer 2 status |
Show a specific interface
1 | //Shows detailed information of interface |
Configure an IP Address
1 | R1(config-if)#ip address 10.255.255.254 ? |
Configure a description per interface
1 | R1(config)#int INTERFACE-ID |
Show the descriptions configured on each interface
1 | R1#show interfaces description |
Switch Interfaces (9)
Show command
1 | SW1#show ip int brief |
Another show command
1 | SW1#show interfaces status |
Another show command; more detailed.
1 | SW1#show interfaces |
Typically, auto-negotiation works fine.
Here’s how to configure the duplex and speed anyways.
1 | SW1#conf t |
Routing (Connected and Local Routes)
Show routes;
Connected and local routes are automatically added for an interface configured with an IP address.
1 | //Connected routes are for a specific network |
Create a route to a network; ensure two way reachability
1 | //Configure a route using the next-hop |
Configure a default route
1 | //Default route is a route to 0.0.0.0/0 |
Subnetting
CIDR Notation Class C
| Dotted Decimal | CIDR Notation | Host bits | Usable Hosts | |
|---|---|---|---|---|
| 255.255.255.0 | /24 | 8 | x.x.x.00000000 | 2^8 - 2 = 254 |
| 255.255.255.128 | /25 | 7 | x.x.x.10000000 | 2^7 - 2 = 126 |
| 255.255.255.192 | /26 | 6 | x.x.x.11000000 | 2^6 - 2 = 62 |
| 255.255.255.224 | /27 | 5 | x.x.x.11100000 | 2^5 - 2 = 30 |
| 255.255.255.240 | /28 | 4 | x.x.x.11110000 | 2^4 - 2 = 14 |
| 255.255.255.248 | /29 | 3 | x.x.x.11111000 | 2^3 - 2 = 6 |
| 255.255.255.252 | /30 | 2 | x.x.x.11111100 | 2^2 - 2 = 2 |
| 255.255.255.254 | /31 | 1 | x.x.x.11111110 | 2^1 - 2 = 0 (2) |
| 255.255.255.255 | /32 | 0 | x.x.x.11111111 | 0 (1) |
For a point-to-point connection, it is possible to use a /31 mask, even though there are no host bits, we can assign the network address and the broadcast address to our two hosts specifically.
In reality, a /30 subnet mask would be used for a point-to-point.
Subnetting Question 1 (Dividing Subnets)
There are four switches, SW1 to SW4, each requiring accommodation for 45 hosts and connected to a central router R1. The task is to subnet the given 192.168.1.0/24 network appropriately.
Divide the 192.168.1.0/24 network into four subnets that can accommodate the number of hosts required.
Determine the number of networks required.
- 45 + 2 = 47
- 47 * 4 = 188 (well within the range of a class C subnet which has 256 subnets)
How to calculate the subnets we need to make?
- /30 gives us 2^2 - 2 = 4 usable addresses
- /29 gives us 2^2 - 2 = 6 usable addresses
- /28 gives us 2^4 - 2 = 14 usable addresses
- /27 gives us 2^5 - 2 = 30 usable addresses
- /26 gives us 2^6 - 2 = 62 usable addresses – this provides us more than we need.
Now calculate each subnet
- Subnet 1: 192.168.1.0 - 192.168.1.63, where
- 192.168.1.0 = network addresses
- 192.168.1.63 = broadcast address
- 192.168.1.1 = first usable
- 192.168.1.62 = last usable
- Subnet 2: 192.168.1.64 - 192.168.1.127 (can simply look at the last bit in the network to determine the going range)
- If we were to do it “manually”…:
- 192.168.1.64 = 11000000.10101000.00000001.[01(000000)] = network address
- 11000000.10101000.00000001.[01(000000)] => x.x.x.[01(111111)] = x.x.x.127
- If we were to do it “manually”…:
- Subnet 3: 192.168.1.128 - 192.168.1.191
- Subnet 4: 192.168.1.192 - 192.168.1.255
- Subnet 1: 192.168.1.0 - 192.168.1.63, where
Subnetting Question 2 (Dividing Subnets)
Divide the 192.168.255.0/24 network into five equal-sized subnets.
- 5 subnets are required.
- /26 is 6 host bits. 2^6 = 64; 64 * 5 = 320, which is well over allocated class C host range.
- /27 is 5 host bits. 2^5 = 32; 32 * 5 = 160, which is within range.
Next, calculate each subnet. – can easily use the network range bit, which is +32.
- 192.168.255.0 - 192.168.255.31 ()
- 192.168.255.32 - 192.168.255.63 IMPORTANT!, it’s not .64!!!!!!!!
- 192.168.255.64 - 192.168.255.95
- 192.168.255.96 - 192.168.255.127
- 192.168.255.128 - 192.168.255.159
Subnetting Question 3 (Which subnet does this belong in?)
~~What subnet does host 192.168.5.57/27 belong to?- /27 indicates 3 ‘borrowed bits’ from x.x.x.001(0000), the 5th bit is 32; so increments of 32. ~
~- 0 -> 32 -> 64, so 192.168.5.57 belongs in the 192.168.5.32/27 subnet (2nd subnet)
A more ‘formal way’ to do this is as follows:
- x.x.x.(001)(11001) = x.x.x.57
- Change all the host bits back to 0 => x.x.x.(001)00000 => x.x.x.32
Subnetting Question 4 (Which subnet does this belong in?)
~~What subnet does host 192.168.29.219/29 belong to?~- /29 => x.x.x.00001000 => 4th bit is 16; so increments of 16. ~
~- 160, 176, 192, 208, 224, 240
~- So 219 is between 208 and 224, so the subnet ID is 192.168.29.208/29. ~~
The more formal way is converting .219 into binary (given that this is a class C address)
- x.x.x.11011011 =>
/29indicates5 borrowed bitsand3 host bits=> x.x.x.(11011)(011) - Now set the host bits to 0 => x.x.x.(11011)000 => x.x.x.208
Subnetting Class B Networks Question 1
Create 80 subnets with the 172.16.0.0/16 network. What prefix length should be used?
The same methods apply to class B as if they were class A, except we begin at the 3rd octet.
xxxxxxxx.xxxxxxxx.00000000.00000000 /16xxxxxxxx.xxxxxxxx.10000000.00000000 /17// 2 subnetsxxxxxxxx.xxxxxxxx.11000000.00000000 /18// 4 subnetsxxxxxxxx.xxxxxxxx.11100000.00000000 /19// 8 subnetsxxxxxxxx.xxxxxxxx.11110000.00000000 /20// 16 subnetsxxxxxxxx.xxxxxxxx.11111000.00000000 /21// 32 subnetsxxxxxxxx.xxxxxxxx.11111100.00000000 /22// 64 subnetsxxxxxxxx.xxxxxxxx.11111110.00000000 /23// 128 subnetsxxxxxxxx.xxxxxxxx.11111111.00000000 /24// 256 subnetsxxxxxxxx.xxxxxxxx.11111111.10000000 /25// 512 subnetsAnswer: The prefix length should be /23.
Subnetting Class B Networks Question 2
Create 500 subnets with the 172.22.0.0/16 network. What prefix length should be used?
xxxxxxxx.xxxxxxxx.00000000.00000000 /16xxxxxxxx.xxxxxxxx.10000000.00000000 /17// 2 subnetsxxxxxxxx.xxxxxxxx.11000000.00000000 /18// 4 subnetsxxxxxxxx.xxxxxxxx.11100000.00000000 /19// 8 subnetsxxxxxxxx.xxxxxxxx.11110000.00000000 /20// 16 subnetsxxxxxxxx.xxxxxxxx.11111000.00000000 /21// 32 subnetsxxxxxxxx.xxxxxxxx.11111100.00000000 /22// 64 subnetsxxxxxxxx.xxxxxxxx.11111110.00000000 /23// 128 subnetsxxxxxxxx.xxxxxxxx.11111111.00000000 /24// 256 subnetsxxxxxxxx.xxxxxxxx.11111111.10000000 /25// 512 subnetsAnswer: Use /25 prefix length.
Subnetting Class B Network Question 3
You have been given the 172.18.0.0/16 network. Your company requires 250 subnets with the same number of hosts per subnet. What prefix length should you use?
8 borrowed bits = 256, which is the closest to meeting the requirement.
x.x.(11111111).00000000 => 16 + 8 = /24 prefix length
Subnetting Class B Network Question 4
What subnet does host 172.25.217.192/21 belong to?
- Same concept as class A, except now we include in the class B (3rd) octet.
- Convert to dotted decimal: x.x.217.192 => x.x.11011001.11000000 => x.x.(11011)(001.11000000)
- Convert all host bits to 0: x.x.(11011)000.00000000 => x.x.216.0/21 subnet, which is the same as 172.25.216.0/21
More Subnetting Questions
Question 1: You have been given 172.30.0.0/16 network. Company requires 100 subnets with at least 500 hosts per subnet. What prefix length should be used?
- Right off the bat, Class C subnets are out of the question. The smallest subnet 2 will likely support only 128 - 2 = 126 hosts.
- Class B subnets should be used here.
- given the 100 subnet requirement…it should be… /16 (0), /17 (2), … 7 borrowed bits… so /23 should be used.
- 9 hosts bits allows for 2^9 - 2 = 510 usable addresses.
Question 2: What subnet does host 172.21.111.201/20 belong to?
- 64 + 32 = 96
- 96 + 8 = 104
- 104 + 4 = 108
- 108 + 2 = 110
- 110 + 1 = 111
Given /20 for a class B subnet, this means 4 borrowed bits, so…
x.x.01101111.xxxxxxxx => I can skip finding the binary form of 201 because /20 is isolated within the 3rd octet.
x.x.(0110)1111.xxxxxxxx => x.x.(0110)0000.xxxxxxxx => x.x.96.xxxxxxxx
Subnet ID: 172.21.96.0/20
Question 3: What is the broadcast address of the network 192.168.91.78/26?
x.x.x.01001100 => x.x.x.(01)001100 => broadcast is all 1’s for host bits => x.x.x.(01)111111 => 192.168.91.127/26
Another way I did it is:
1 | Class B, so... |
Question 4: You divide the 172.16.0.0/16 network into 4 subnets of equal size. Identify the NETWORK and BROADCAST addresses of the 2nd subnet.
| Prefix Length | Number of Subnets | Number of Hosts per Subnet | Total Number of Hosts… |
|---|---|---|---|
| /17 | 2 | 32766 | 32768 |
| /18 | 4 | 16382 | 16384 |
| /19 | 8 | 8190 | 8192 |
| /20 | 16 | 4094 | 4096 |
| /21 | 32 | 2046 | 2048 |
| /22 | 64 | 1022 | 1024 |
| /23 | 128 | 510 | 512 |
| /24 | 256 | 254 | 256 |
| /25 | 512 | 126 | 128 |
| /26 | 1024 | 62 | 64 |
| /27 | 2048 | 30 | 32 |
| /28 | 4096 | 14 | 16 |
| /29 | 8192 | 6 | 8 |
| /30 | 16384 | 2 | 4 |
| /31 | 32768 | 0 (2) | 2 |
| /32 | 65536 | 0 (1) | 1 |
4 subnets? Should be 2 borrowed bits (which is equal to 4 subnets).
Therefore, it’s /18 prefix.
x.x.(00)xxxxxx.xxxxxx (notice that the 2 borrowed bits, 00, 01, 10, 11, – are the only possible options)
The 2nd subnet would be 01, which is x.x.(01)xxxxxx.xxxxxx.
Network address is 172.16.64.0.
The broadcast address would be all 1’s in host bits. So, x.x.x(01)111111.11111111 = 172.16.127.255 (?)
You divide the 172.30.0.0/16 network into subnets of 1000 hosts each. How many subnets are you able to make? —!!!!!!!!!!
If we don’t have access to the chart,
1 | - Even if we don't know it, we can start at /32. |
Actually, we can just do it normally.
2^n - 2 = 1000~ ? , where n = HOST bits (not network bits). Need about 10 host bits.
2^1 - 2 = 1024 - 2 = 1022;
Okay. We’re left with 6 borrowed bits.
x.x.x.(xxxxxx)(xx.xxxxxxxx)
So, if the prefix is /22, then the amount of subnets is therefore 2,4,6…64 subnets.
Subnetting Class A Networks
Question 1: “You have been given the 10.0.0.0/8 network. You must create 2000 subnets which will be distributed to various enterprises. What prefix length must you use? How many host addresses (usable addresses) will be in each subnet?”
- Let’s see how many network bits we need to create 2000 subnets.
- 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048 => 11!
- x.(xxxxxxxx.xxx)xxxxx.xxxxxxxx =
/19is the prefix length. - There are 13 host bits remaining. So 2^13 - 2 = 8192 - 2 = 8190 host.
Question 2:
PC1 has an IP address of 10.217.182.223/11.
Identify the following for PC1’s subnet:
- Network address:
- Broadcast address:
- First usable address:
- Last usable address:
- Number of host (usable) addresses:”
x.11011001.xxxxxxxx.xxxxxxxxx ; given the /11 subnet, we don’t technically need the rest.
x.(110)11001.xxxxxxxx.xxxxxxxxx ; /11 is 3 borrowed bits.
- Network address: x.(110)00000.00000000.00000000 => 10.192.0.0/11
- Broadcast address: x.(110)11111.11111111.11111111 => 10.223.255.255/11
- First usable: 10.192.0.1
- Last usable address: 10.223.255.254
- Number of host (usable addresses): 21 host bits => 2^21 - 2 = 2,097,150 hosts
VLSM
- Assign the largest subnet a the start of the address space.
- Assign the 2nd largest after.
- Repeat until largest to smallest.
Given 192.168.1.0/24 use VLSM to create 5 subnets for all hosts.
Tokyo LAN A (110) -> Toronto LAN B (45)-> Toronto LAN A (29) -> Tokyo LAN B (8) -> P2P (1)
Tokyo LAN A:
1 | 110 hosts, means 2,4,8,16,32,64,128, which is 7 host bits; leaving us with 1 network bit in the /24 network. |
Toronto LAN B
1 | 45 hosts means 2,4,8,16,32,64, which is 6 host bits; leaving us with 2 network bits in the /24 network. |
Toronto LAN A
1 | 29 hosts means 2,4,8,18,32, which is 5 host bits; leaving us with 3 network bits in the /24 network. |
Tokyo LAN B
1 | 8 hosts means 2,4,8,16, which is 4 host bits; leaving us with 4 network bits in the /24 network. |
P2P Between R1 and R2
1 | P2P connections should use a /30 network, which leaves us with 2 host bits. |
VLANs (Access Ports)
After configuring subnets and default gateways on end hosts, (and setting router interfaces to their respective default gateway for each planned VLAN…)
Show VLANs
1 | //All vlans are in in VLAN 1 by default; 1002 - 1005 exist by deault and cannot be deleted. |
VLAN Configuration
Assign VLAN(s) to interfaces
1 | SW1(config)#interface range g1/0 - 3 |
Configure VLANs
1 | //Define a name |
VLANs (Trunk Configurations - manual)
Manually configure interface as a trunk;
Modern switches do not support ISL, but for switches that do, you’d need to configure the encapsulation mode first; switches that only support dot1q will not need to do this
1 | SW1(config)#interface g0/0 |
Show command
1 | SW1#show interfaces trunk |
Configured VLAN Allowed; configuring allowed VLANs is good for security and performance
1 | SW1(config)#interface g0/0 |
Change the native VLAN; ensure NATIVE VLAN matches between switches
1 | SW1(config-if)#switchport trunk native vlan VLAN-ID |
Difference between show vlan brief and show interfaces trunk
- Interfaces configured with trunk ports will NOT show up in
show vlan brief; Useshow interfaces trunk1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30SW1#show vlan brief
VLAN Name Status Ports
---- -------------------- ---------- -------------------------------------
1 default active Gi1/1, Gi1/2, Gi1/3, Gi2/0
Gi2/1, Gi2/2, Gi2/3, Gi3/0
Gi3/1, Gi3/2, Gi3/3
10 ENGINEERING active Gi0/1, Gi0/2
30 SALES active Gi0/3, Gi1/0
1002 fddi-default act/unsup
1003 token-ring-default act/unsup
1004 fddinet-default act/unsup
1005 trnet-default act/unsup
SW1#
SW1(config-if)#do show interfaces trunk
Port Mode Encapsulation Status Native vlan
Gi0/0 on 802.1q trunking 1001
Port Vlans allowed on trunk
Gi0/0 10,30
Port Vlans allowed and active in management domain
Gi0/0 10,30
Port Vlans in spanning tree forwarding state and not pruned
Gi0/0 10,30
SW1(config-if)#
Router on a Stick (ROAS)
Inter-VLAN routing is achieved via packet routes that are sent to the switch, then routed to a router. The router identifies the encapsulation (dot1q/ISL) tag via the VID, then routes it to the sub-interfaces as if they were individual interfaces.
Enter sub-interface configuration mode
Method 1: For sub-interfaces
1 | //Remember that router intefaces are shutdown by default; enable via `no shutdown` in the base interface |
Native VLAN Configurations on the Router
Method 1: Configuring a Native VLAN on a sub-interface (assuming the IP address is already configured)
The configuration below achieves the goal that packets that are destined for VLAN 10 will not be tagged with the dot1q frame in the ethernet frame. Assuming that switches are configured with the same native VLAN, untagged frames will be routed to their native configured VLAN; achieves efficiency, but security issue.
1 | R1(config)#int g0/0.10 |
Method 2: The configuration here already assumes that we set up sub-interfaces with encapsulation and dot1q.
So, we simply change the sub-interface (and its respective VLAN) to a regular interface and IP address/gateway.
1 | R1(config)#no interface g0/0.10 |
Multilayer Switches (Layer 3)
- Introduces switch virtual interfaces (SVI).
- Each PC should be configured to use the SVI (not the router) as their gateway address.
- In addition to SVI, we can also configure switch interfaces to act like router interfaces.
Multilayer switches are the preferred method of inter-VLAN routing in a busy network.
In ROAS, end points were configured to use the router as the default gateway. Instead, configure the default-gateway to be the switch virtual interface (SVI).
Then what about routing traffic to the internet not meant for any VLAN?
- We can configure IP addresses between the multilayer switch and router. Then create a default route in the routing table (like a router).
Multilayer Switch Configuration for Point-to-Point; Point-to-Point Link for Switch and Router
Swap a sub-interface trunk router with a a multilayer switch Point-to-Point configuration
1 | // disable router's ROAS configuration if configured. |
1 | //Configure a regular IP address as normal for a P2P |
Multilayer Switch Configuration for Point-to-Point; enable multilayer switch to handle inter-VLAN routing
Here, we enable
ip routingon a switch for layer 3 functionality, and also change a switch port to a “routed port (router port)”1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//If already configured, reset
SW2(config)#default interface INTERFACE-ID
// enables Layer 3 routing on the switch ; DO NOT FORGET
SW2(config)#ip routing
// configures the interface as a "routed port" instead of a switch port;
SW2(config)#interface INTERFACE-ID
SW2(config-if)#no switchport
// now we can configure an IP address on the interface like a regular router interface
SW2(config-if)#ip address IP-ADDRESS SUBNET-MASK
SW2(config-if)#do show ip interface brief
Interface IP-Address OK? Method Status Protocol
GigabitEthernet0/0 unassigned YES unset up up
GigabitEthernet0/2 unassigned YES unset up up
GigabitEthernet0/3 unassigned YES unset up up
GigabitEthernet0/1 192.168.1.193 YES manual up up
GigabitEthernet1/0 unassigned YES unset up up
GigabitEthernet1/1 unassigned YES unset up up
GigabitEthernet1/2 unassigned YES unset up up
GigabitEthernet1/3 unassigned YES unset up up
GigabitEthernet2/0 unassigned YES unset up up
GigabitEthernet2/1 unassigned YES unset up upConfigure a default route so that traffic meant for the internet is sent to the router (given that SW and R are P2P)
1
SW2(config)#ip route 0.0.0.0 0.0.0.0 NEXT-HOP
Now, Configure SVI Configuration
SVI’s here are used for default gateways, much like a router. So instead of sub-interfaces in routers, switches can just create SVIs.
1 | // creates SVI for VLAN 10 // SVI's are shutdown by default; to enable use 'no shutdown' |
Conditions for SVI to be up/up
- The VLAN must exist on the switch. SVI’s do not automatically create a VLAN on the switch.
- The switch must have at least one access port in the VLAN up/up state, AND/OR one trunk port that allows the VLAN that is in an up/up state.
- The VLAN must not be shutdown.
- The SVI must not be shutdown.
DTP/VTP : should be disabled (N)
DTP
DTP will not form a trunk with a router, PC, etc. Switchports here will be in access mode by default.
1 | SW2(config-if)#switchport mode ? |
DTP will auto-negotiate encapsulation mode for ISL (first) or 802.1Q (if available)
1 | SW1(config-if)#switchport mode dynamic desirable |
Disable auto-negotiate
1 | //disable auto-negotiation as follows: |
VTP
VTP is a virtual LAN trunking protocol used to shared VLAN information between devices; switches act as central VTP servers that advertise their VLAN databases. (VTP does not assign vlans to interfaces )
VTP is designed for large networks, but it’s not recommended.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18SW1#show vtp status
VTP Version capable : 1 to 3
VTP version running : 1
VTP Domain Name :
VTP Pruning Mode : Disabled
VTP Traps Generation : Disabled
Device ID : c0c9.f956.1300
Configuration last modified by 0.0.0.0 at 0-0-00 00:00:00
Local updater ID is 0.0.0.0 (no valid interface found)
Feature VLAN:
VTP Operating Mode : Server
Maximum VLANs supported locally : 1005 // VTPv1/v2 do not support extended VLAn range (1006-4094)
Number of existing VLANs : 5
Configuration Revision : 0
MD5 digest : 0x57 0xCD 0x40 0x65 0x63 0x59 0x47 0xBD
0x56 0x9D 0xA4 0x3E 0xA5 0x69 0x35 0xBCCisco switches operate VTP server mode by default
VTP servers and clients will sync with each other with the highest revision number (if in the same domain)
VTP Transparent does not participate in the VTP domain (does not sync VLAN database)
- Transparent mode forwards other VTP advertisements, but will not send its own database advertisements.
VTP Client mode cannot create VLANs
How to reset revision domain? Change domain name to an unused, or change VTP mode to transparent.
VTPv1/v2 do not support extended VLAN range (1006-4094)
1 | //COMMANDS |
Show
1 | show vtp status |
STP (Analyzing STP)
- Hello BDPU’s are sent by forwarding states; it indicates to the receiving interface that the connected device is a switch; since routers, PCs, (etc), do not send Hello BDPUs.
- Interfaces that do not receive BPDU’s can safely go into forwarding mode.
- Originally, a bridge ID is the bridge priority (32768) + MAC address.
- Bridge priority became => bridge priority + extended system ID (VLAN ID)
- Why add VLAN ID? ; Cisco switches use PVST, which runs a separate STP instance in each VLAN, so difference interfaces can be forwarding/blocking.
- Why is the bridge priority 32768? 16 bits for bridge priority => most significant bit set to 1.
- But actually, since VLAN ID default is 1; it’s 32768 + 1 = 32769
- You can only change the bridge ID by 4096? Why? Since extended system ID cannot change (VLAN ID). The 4th bit of the far most 16th bit is 4096.
- Bridge priority became => bridge priority + extended system ID (VLAN ID)
| Bridge Priority | 32768 | 16384 | 8192 | 4096 |
|---|---|---|---|---|
| Binary Value | 0 | 1 | 1 | 1 |
| Extended System ID (VLAN ID) | 2048 | 1024 | 512 | 256 | 128 | 64 | 32 | 16 | 8 | 4 | 2 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Binary Value | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
28673 (16384 + 8192 + 4096 + 1)
- In 802.1D, all interfaces on the root bridge are designated ports.
- When a switch is powered on, it assumes root bridge; a lower bridge ID (superior BPDU) will force it give up its position.
| STP Port State | Send/Receive BPDUs | Frame forwarding (regular traffic) | MAC address learning | Stable/Transitional |
|---|---|---|---|---|
| Blocking | NO/YES | NO | NO | Stable |
| Listening | YES/YES | NO | NO | Transitional |
| Learning | YES/YES | NO | YES | Transitional |
| Forwarding | YES/YES | YES | YES | Stable |
| Disabled | NO/NO | NO | NO | Stable |
Spanning Tree Protocol Determination
One switch is elected as the root bridge. All ports on the root bridge are designated ports (forwarding state). Root bridge selection:
1: Lowest bridge IDEach remaining switch will select ONE of its interfaces to be its root port (forwarding state). Ports across from the root port are always designated ports.
Root port selection:
1: Lowest root cost
2: Lowest neighbor bridge ID
3: Lowest neighbor port IDEach remaining collision domain will select ONE interface to be a designated port (forwarding state). The other port in the collision domain will be non-designated (blocking)
Designated port selection:
1: Interface on switch with lowest root cost *** compare the routes
2: Interface on switch with lowest bridge ID
Show commands
1 | SW3#show spanning-tree |
1 | // To see the total "cost" (root path), use: |
Spanning Tree - 2
- STP is enabled by default, but we can still configure root switches and such.
A port can move from the non-designated to listening to learning state in a total of 50 seconds by default.
- 20 seconds (2x10 (hello timer))
- 15 seconds listening
- 15 seconds learning
Port fast can be enabled on end-hosts. The process of forming a layer 2 loop only occurs with other switches. End-hosts have no risk of forming loops, so enabling portfast subverts the listening and learning process normally required.
- Warning: one of which indicates that portfast should be enabled on a port with a single host.
- Warning: must be an access port; since trunk ports are normally reserved for more than one.
1
2
3
4
5
6
7//Assuming an END-HOST
SW1(config)#interface g0/2
SW1(config-if)#spanning-tree portfast
%Warning: portfast should only be enabled on ports connected to a single host. Connecting hubs, concentrators, switches, bridges, etc... to this interface when portfast is enabled, can cause temporary bridging loops. Use with CAUTION
%Portfast has been configured on GigabitEthernet0/2 but will only have effect when the interface is in a non-trunking mode.
SW1(config-if)#
Since spanning-tree only works on access ports, we can enable portfast on all access ports as follows:
1 | //enables spanning-tree on all access ports, but not trunk ports |
What if Portfast is enabled, but an unwitting employee plugs in another switch?
- BDPU Guard: since end hosts do not send BPDU messages, if an interface with portfast is enabled receives a BPDU, then the interface is shutdown.
1
2//BPDU guard for interface-specific
SW(config-if)#spanning-tree bpuguard enable
1 | //BPDU guard for all portfast enabled interfaces // global enable |
Other spanning-tree optional
1 | Root Guard |
Configure the spanning-tree mode
1 | SW1(config)#spanning-tree mode ? |
Manually configure the root bridge;
Useful for STP-Load Balancing amongst different VLANs
1 | //configure Root bridge // sets to priority 24576 (or 4096 less than the lowest) |
Show command
1 | //show info |
Configuring Spanning-Tree Port Settings
1 | SW1(config)#spanning-tree vlan 1 ? |
RSTP (Rapid PVST+) (Kinda the same thing)
About RSTP
Cisco’s summary:
“RSTP is not a timer-based spanning tree algorithm like 802.1D. Therefore, RSTP offers an improvement over the 30 seconds or more that 802.1D takes to move a link to forwarding. The heart of the protocol is a new bridge-bridge handshake mechanism, which allows ports to move directly to forwarding.”
- RSTP serves the same purpose as STP.
- RSTP elects a root bridge with the same STP rules (802.1D)
- RSTP elects a root PORT with the same STP rules (802.1D)
- RSTP elects the designated ports with the same STP rules (802.1D)
Table comparing the Spanning Tree Protocol (STP) costs to the Rapid Spanning Tree Protocol (RSTP) costs based on network speed:
| Speed | STP Cost | RSTP Cost |
|---|---|---|
| 10 Mbps | 100 | 2,000,000 |
| 100 Mbps | 19 | 200,000 |
| 1 Gbps | 4 | 20,000 |
| 10 Gbps | 2 | 2,000 |
| 100 Gbps | X | 200 |
| 1 Tbps | X | 20 |
The blocking and disabled state from STP 802.1D is now combined into the “discarding” state
| STP Port State | Send/Receive BPDUs | Frame forwarding (regular traffic) | MAC address learning | Stable/Transitional |
|---|---|---|---|---|
| Discarding | NO/YES | NO | NO | Stable |
| Learning | YES/YES | NO | YES | Transitional |
| Forwarding | YES/YES | YES | YES | Stable |
The root port role remains unchanged in RSTP.
→ The port that is closest to the root bridge becomes the root port for the switch.
→ The root bridge is the only switch that doesn’t have a root port.The designated port role remains unchanged in RSTP.
→ The port on a segment (collision domain) that sends the best BPDU is that segment’s designated port (only one per segment)The non-designated port role is split into two separate roles in RSTP:
- the alternate port role
- the backup port role
What is an alternate port?
- A port that can become the root port in case of failure.
What is a backup port? - A port that can become a designated port.
- A backup port receives a superior BPDU from ANOTHER interface on the SAME switch. So, like in a hub–often won’t encounter.
- The lowest port ID is selected as the designated port.
What is uplink fast? (N)
- The alternate port is a discarding (blocked) port (like in STP).
- Its appointment is the same as designating block ports in regular STP.
- However, alternate ports have the ability to become the root port if its own switch’s root port fails. (This is an optional feature of STP, but automatically incorporated in RSTP)
What is backbone fast? - Basically, speeds up the response to indirect network link failures in Spanning Tree Protocol, allowing the network to recover faster without waiting for the usual timers to expire.
Other:
Rapid PVST is compatible with Classic STP with the same interfaces connected to a switch running classic STP
Classic STP Protocol Identifier: 0
RSTP Protocol Identifier: 2
Classic STP BPDU Flags: only 2
RSTP BPDU Flags: all 8 are used
Classic STP: only root bridge originated BPDUs, and other switches forward BPDU recieved.
RSTP: ALL switches originate and send their own BPDUs from designated ports.
Classic STP: ages much slower; waits 10 hello intervals (20 seconds)
RSTP: considers a neighbor lost if it misses 3 BPDUs (6 seconds); then flushes all learned MAC addresses on that interface.
RSTP Link Types
- Edge: a port that is connected to end host; moves directly to forwarding without negotiation (like portfast in classic STP)
- In fact, you configure an edge-port by simply enabling portfast:
SW1(config-if)# spanning-tree portfast
- In fact, you configure an edge-port by simply enabling portfast:
- Point-to-point: a direct connection between switches
- Shared: a connection to a hub; must operate in half-duplex (not used)
RSTP Determination
https://youtu.be/EpazNsLlPps?si=U0PKiRISExD9HF2r&t=2272
EtherChannel (Port Channel / LAG) and Load Balancing
- Adding extra links to an access-layer switch doesn’t help. Why? Spanning-tree protocol will disable interfaces.
- To solve this problem, we can group interfaces logically into a single interface to behave as if it is a single link but with better throughput.
- EtherChannel load balances based on ‘flows’; basically, the same “interface” will be used for the same connection.
Check load-balancing
1 | ASW1#show etherchannel load-balance |
Types of load-balancing criteria
1 | ASW1(config)#port-channel load-balance ? |
Configure load-balancing
1 | ASW1#conf t |
Take note that to configure load-balance; use port-channel
And to view load-balance… it’s etherchannel…
Creating EtherChannels (PAgP / LACP) (N)
- PAgP (Port aggregation Protocol); Cisco proprietary
- Dynamically negotiates the creation and maintenance of EtherChannel
- LACP (Link Aggregation Control Protocol)
- Industry standard (IEEE 802.3ad)
- Dynamically negotiates the creation and maintenance of EtherChannel
- Static EtherChannel Configurations
- No automatic forming of etherchannels; usually avoided* but has its use.
Up to 8 interfaces can be active (LACP allows for 16, but only 8 active and 8 standby)
For PAgP:
- auto + auto = no EtherChannel
- desirable + auto = EtherChannel
- desirable + desirable = EtherChannel
For LACP:
- passive + passive = no EtherChannel
- active + passive = EtherChannel
- active + active = EtherChannel
For Static:
- on + on = etherchannel
- no other configurations or variations (e.g., on + desirable) will work
Configure an interface to be part of an EtherChannel
channel-groups MUST match on the SAME switch, but can vary on different switches…
1 | //Configure the necessary interfaces; preferred method since configs MUST match |
Configure the protocol itself;
- The command is not very useful as configuring the
desirable/autooractive/passivewill set the protocol, but here it is.
1 | ASW1(config-if-range)#channel-protocol ? |
Now that you’ve created and logically grouped interfaces into an etherchannel, we can configure the etherchannel itself: (ensure configurations are the same on both devices)
1 | ASW1(config)#interface port-channel 1 |
Notice that the port-channel configuration for the etherchannel is applied to ALL applicable interfaces within that etherchannel/port-channel group.
1 | interface Port-channel |
EtherChannel Troubleshooting:
- Member interfaces must have matching duplex, speed, switchport mode (access/trunk), and same allowed VLANs/same native VLANs (for trunk interfaces)
Another Useful Show Command
1 | ASW1#show etherchannel summary |
Layer 3 Multi-Switches and EtherChannels
- Routed ports are layer 3, and therefore do not forward layer 2 broadcasts. So no spanning-tree is even required.
- This is done so that traffic is load-balanced.
Configure a Layer 3 EtherChannel
1 | ASW1(config)#int range g0/0 - 3 |
Since we want all links to act as a single logical link, the ip-address should be configured on the port-channel interface.
1 | ASW1(config-if-range)#int po1 |
Show command; should be good
1 | ASW1(config-if)#do sh etherch sum |
Dynamic Routing - 24
| Route protocol/type | AD |
|---|---|
| Directly connected | 0 |
| Static | 1 |
| External BGP (eBGP) | 20 |
| EIGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| IS-IS | 115 |
| RIP | 120 |
| EIGRP (external) | 170 |
| Internal BGP (iBGP) | 200 |
| Unusable route | 255 |
Change the AD of a routing protocol
1 | ? |
Change the AD of a static route
1 | R1(config)#ip route IP-ADDRESS SUBNET-MASK NEXT-HOP AD-DISTANCE-METRIC |
1 |
RIP and EIGRP - 25 (Configurations - (N))
RIP
Routing Information Protocol (industry standard)
Distance vector IGP (uses routing-by-rumor logic to learn/share routes)
Uses hop count as its metric. One router = one hop (bandwidth is irrelevant!)
The maximum hop count is 15 (anything more than that is considered unreachable)
Has three versions:
- RIP v1 and RIP v2, used for IPv4
- RIPng (RIP Next Generation), used for IPv6
Uses two message types:
- Request: To ask RIP-enabled neighbor routers to send their routing table
- Response: To send the local router’s routing table to neighboring routers
By default, RIP-enabled routers will share their routing table every 30 seconds
RIP v1:
- only advertises classful addresses (Class A, Class B, Class C)
- doesn’t support VLSM, CIDR
- doesn’t include subnet mask information in advertisements (Response messages)
- 10.1.1.0/24 will become 10.0.0.0 (Class A address, so assumed to be /8)
- 172.16.192.0/18 will become 172.16.0.0 (Class B address, so assumed to be /16)
- 192.168.1.4/30 will become 192.168.1.0 (Class C address, so assumed to be /24)
- messages are broadcast to 255.255.255.255
RIP v2:
- supports VLSM, CIDR
- includes subnet mask information in advertisements
- messages are multicast to 224.0.0.9
RIP Configuration (N)
1 | R1(config)#router rip |
The network command doesn’t tell the router which networks to advertise. It tells the router which interfaces to activate RIP on, and then the router will advertise the network prefix of those interfaces (which is NOT the prefix in the network command).
Even if a network command enables an interface, if the interface has no neighbors, no new adjacencies are formed. It’s best to disable unnecessary traffic as these interfaces will continuously send RIP advertisements.
Passive-interface
1 | //Disables the interface from sending RIP advertisements out of specified interface; but will still allow the interface to be advertised to its RIP neighbors via other interfaces. |
Configure a default route into RIP and then SHARE the default route to neighbors
1 | //Configure default route |
Show command
1 | //Used for RIP, EIGRP, OSPF |
Change the maximum paths (same for RIP, EIGRP, OSPF)
1 | R1(config-router)#maximum-paths <1-32> |
Change AD; if for some reason you want RIP to have a higher priority (lower AD) (same for RIP, EIGRP, OSPF)
1 | R1(config-router)#distance ? |
EIGRP: Enchanced Interior Gateway Routing Protocol
- Cisco properity, semi open source, faster than RIP, no hop-count limit of 15 (RIP), and multicast address 224.0.0.10
- EIGRP is the only IGP that performs unequal-cost load balancing)
- (But by default, performs ECMP load-lancing over 4 paths like RIP)
EIGRP Configuration
1 | R1(config)#router eigrp AS-NUMBER |
The AS (Autonomous System) number must match between routers, or they will not form an adjacency and share route information.
Auto-summary might be enabled or disabled by default, depending on the router/IOS version. If it’s enabled, disable it.
The network command will assume a classful address if you don’t specify the mask.
Wildcard Mask (Inverted Subnet Mask)
- A wildcard mask is basically an ‘inverted’ subnet mask.
- All 1s in the subnet mask are 0 in the equivalent wildcard mask. All 0s in the subnet mask are 1 in the equivalent wildcard mask.
1 | 11111111.11111111.11111111 .00000000 // subnet mask for /16 |
/28
1 | 11111111.11111111.11111111 .11110000 // subnet mask for /28 |
/25
1 | 11111111.11111111.11111111 .10000000 // subnet mask for /25 |
/14
1 | 11111111.11111100.00000000.00000000 // subnet mask for /14 |
/19
1 | 11111111.11111111.11100000.00000000 // subnet mask for /19 |
Shortcut method: subtract each octet of the subnet task from 255.
Wildcark Masks are used as follows:
- ‘0’ in the wildcard mask = must match
- ‘1’ in the wildcard mask = do not have to match
For example:
1 | EIGRP network command: |
This means that the first 28 bits MUST match.
So does 172.16.1.14 match? Yes
1 | (10101100 . 00010000 . 00000001 . 0000)1110 |
As you can see, the first 28 bits match the original network command.
1 | R1#show ip protocols |
First, EIGRP metric is determined via interface bandwidth and delay by default indicated by:
1 | Metric weight K1=1, K2=0, K3=1, K4=0, K5=0 |
The bandwidth of the slowest link + sum of delay values of all the link in the paths.
Second, the router ID shown just serves as a unique identifier for each router participating in EIGRP routing domain. It looks like an IP-address but it’s not, and that’s simply because of the way it was derived.
1 | Router-ID: 172.16.1.14 |
The router ID order of priority is as follows:
- Manual Configuration
- Highest IP address on a loopback interface
- Highest IP address on a physical interface (ANY)
Or we can manually set the router ID as follows:1
2
3
4R1(config-router)#eigrp router-id ?
A.B.C.D EIGRP Router-ID in IP address format
R1(config-router)#eigrp router-id 1.1.1.1
Lastly, notice the maximum paths, auto-summarization, network routes, configured passive-interfaces, and administrative distance values (AD)
1 | Automatic Summarization: disabled |
Finally, EIGRP is indicated by “D” in show ip routes, not “E”
1 | R1#show ip route |
EIGRIP Configurations (N); Info (Y)
- Feasible Distance = This router’s metric value to the route’s destination.
- Reported Distance (aka Advertised Distance) = The neighbor’s metric value to the route’s destination.
- Successor = the route with the lowest metric to the destination (the best route)
- Feasible Successor = an alternate route to the destination (not the best route) which meets the feasibility condition
EIGRP maximum metric variance is 1, which means it cannot perform unequal-cost load-balancing given two routes with varying feasible distances.
Routes MUST meet the feasible “successibility” requirements for unequal-cost load-balancing: a route is considered a feasible successor if its REPORTED DISTANCE is lower than the SUCCESSOR route’s FEASIBLE DISTANCE
1 | R1#show ip protocols |
Generalized Steps for EIGRP Configurations
1 | //Configure EIGRP by specifying the autonomous system number; all routers must share the same AS number |
OSPF Part 1
OSFP is a “link-state” routing protocol, which creates a complete map of the network; and every device has the same database of routing information stored.
Generalized OSPF Configurations
1 | //Process IDs are locally significant, and unlike EIGRP do not require the numbers to be the same |
OSPF - 2
Neighbor States
OSPF Neighbor Discovery and Formation
- Hello Packets: OSPF routers send Hello packets to the multicast address 224.0.0.5 on an Ethernet network. These packets are used to discover and maintain adjacency with other OSPF routers.
- Neighbor States: OSPF routers go through several states as they establish and maintain a full adjacency:
- Down: Initial state, no information has been received on this interface.
- Init: Router has detected a Hello packet from a neighbor, but two-way communication has not yet been established.
- 2-Way: Bidirectional communication is established. OSPF routers decide whether to become fully adjacent based on criteria such as the router ID, area ID, and network type.
- ExStart: Routers establish a master-slave relationship and determine the sequence number for exchanging OSPF link-state databases.
- Exchange: Routers exchange database descriptor packets summarizing their link-state databases.
- Loading: Routers request more detailed information about any entries in the link-state database that are newer or missing.
- Full: Routers have full knowledge of each other’s routing information and the adjacency is complete.
Criteria for Forming Neighbors
- Matching Hello and Dead Intervals: Routers must agree on the Hello and Dead intervals to form a neighbor relationship.
- Same Subnet: Routers must be on the same subnet to communicate OSPF messages.
- Area ID: Routers must belong to the same OSPF area on a particular interface.
- Authentication: If OSPF authentication is configured, the authentication type and credentials must match.
Maintenance of OSPF Neighbors
- Timers: OSPF uses several timers to manage neighbor relationships and ensure the network’s stability:
- Hello Timer: Determines how frequently Hello packets are sent.
- Dead Timer: Specifies how long a router waits without receiving a Hello packet before declaring the neighbor down.
OSPF Neighbor Requirements
Area Numbers must match
Interfaces must be in the same subnet
OSPF process must not be shutdown
OSPF router ID’s must be unique
Set OSPF hello and dead timers
1
2
3
4
5//sets hello-interval
R1(config-if)#ip osp hello-interval SEC
//sets dead-interval
R1(config-if)#ip ospf dead-interval SECSet OSPF password
1
2
3
4
5//set passwords -- OSPF adj must have the same password
R1(config-if)#ip ospf authentication-key PASSWORD
//must enable
R1(config-if)#ip ospf authenticationConfigure IP MTU (OSPF will still be on if not matching neighbors, but won’t work properly)
1
R1(config-if)#ip mtu <68-1500>
OSPF Network Type must match
- If we configure a loopback address, and then change the physical interface; might be an issue and still display FULL.
1
R1(config-if)#
- If we configure a loopback address, and then change the physical interface; might be an issue and still display FULL.
Enable OSPF Directly on an Interface without using the Network Command
1 | R1(config)#int INT-ID |
Serial Interface’s
1 | //Default encapsulation is HDLC |
OSPF - 3
https://www.youtube.com/watch?v=3ew26ujkiDI&list=PLxbwE86jKRgMpuZuLBivzlM8s2Dk5lXBQ&index=53
DR/BDR Selection
The DR/BDR election order of priority:
- Highest OSPF interface priority
- Highest OSPF Router ID
‘First place’ becomes the DR for the subnet, ‘second place’ becomes the BDR
Default OSPF priority is 1 on all interfaces; so likely router ID will be used unless otherwise configured.
- The router ID itself has its own selection; manual configuration -> loopback -> physical IP
Change the OSFP interface priority to affect DR/BDR Selection
1 | R2(config)#int g0/0 |
DR/BDR is non-preemptive, which means DR/BDR will keep their roles unless OSPF is reset (not recommended), or the interface fails/resets.
→ When the DR goes down, the BDR becomes the new DR. Then an election is held for the next BDR.
→ DROthers will only move to the FULL state with the DR and BDR. The neighbor state with other DROthers will be 2-way.
Change the network type:
1 | R1(config-if)#ip ospf network ? |
FHRP (HSRP) Configuration (N)
The role of FHRP is to automatically swap the default gateway of end hosts to a new default gateway if the route does down.
When FHRP is configured, a virtual IP address and a virtual MAC address is used.
- Routers with FHRP will negotiate via Hello messages for Active/Standby, then if router goes down, the standby/backup will become the new Active, and only the switches MAC address table needs to be updated via gratuitous ARP replies.
FHRPs are also non-preemptive, but can be changed.
In short:
- A virtual IP is configured on the two routers, and a virtual MAC is generated for the virtual IP (each FHRP uses a different format for the virtual MAC).
- An active router and a standby router are elected. (different FHRPs use different terms)
- End hosts in the network are configured to use the virtual IP as their default gateway.
- The active router replies to ARP requests using the virtual MAC address, so traffic destined for other networks will be sent to it.
- If the active router fails, the standby becomes the next active router. The new active router will send gratuitous ARP messages so that switches will update their MAC address tables. It now functions as the default gateway.
- If the old active router comes back online, by default it won’t take back its role as the active router. It will become the standby router.
- You can configure ‘preemption’, so that the old active router does take back its old role.
HSRP
- Cisco proprietary.
- An active and standby router are elected.
- There are two versions: version 1 and version 2.
- Version 2 adds IPv6 support and increases the number of groups that can be configured.
- Multicast IPv4 address:
- v1 = 224.0.0.2
- v2 = 224.0.0.102
- Virtual MAC address:
- v1 = 0000.0c07.acXX (XX = HSRP group number)
- v2 = 0000.0c9f.fXXX (XXX = HSRP group number)
- In a situation with multiple subnets/VLANs, you can configure a different active router in each subnet/VLAN to load balance.
VRRP
- Open standard
- A master and backup router are elected.
- Multicast IPv4 address: 224.0.0.18
- Virtual MAC address: 0000.5e00.01XX (XX = VRRP group number)
- In a situation with multiple subnets/VLANs, you can configure a different master router in each subnet/VLAN to load balance.
GLBP
- Cisco proprietary
- Load balances among multiple routers within a single subnet
- An AVG (Active Virtual Gateway) is elected.
- Up to four AVFs (Active Virtual Forwarders) are assigned by the AVG (the AVG itself can be an AVF, too)
- Each AVF acts as the default gateway for a portion of the hosts in the subnet.
- Multicast IPv4 address: 224.0.0.102
- Virtual MAC address: 0007.b400.XXYY (XX = GLBP group number, YY = AVF number)
HSRP Configuration (N)
How is the active router determined?
- Highest priority - default 100
- Highest IP address
1 | R1(config-if)#standby ? |
Do the same configurations for the other redundant router, including version, same virtual IP. \
1 | Basic HSRP Configuration |
IPv6 Routing
Configure IPv6 on Router Interfaces
1 | R1(config)#ipv6 unicast-routing // enables ipv6 routing ; enables ipv6 forwarding; does not affect R's ability to send and recieve its own ipv6 traffic |
1 | R1#show ipv6 neighbor // displays ipv6 neighbor table |
SLAAC
1 | ipv6 address autoconfig // dont need to enter prefix; NDP is used to learn the prefix used on the local link, and devices will use eui-64 to generate the interface ID (or randomly generate depending) |
IPv6 Static routing
1 | R1#show ipv6 route // shows connected and local; does not show link-local |
1 | ipv6 route destination/prefix-length (next-hop | exit-interface [next-hop]) [ad] |
1 | Network route: |
ACL
Numbered ACL
1 | R1(config)#access-list NUMBER {deny | permit} ip wildcard-mask |
By default, the ACL is configured /32 if a wildcard-mask is not given.
1 | //Specifies wildcard /32 mask |
Implicit allow
1 | R1(config)#access-list 1 permit any |
Remark
1 | R1(config)#access-list 1 remark DESCRIPTION |
Show
1 | //Displays all kinds of ACLs |
Apply to an interface
1 | R1(config-if)#ip access-group NUMBER {in | out} |
Standard Named ACLs
Configuration
1 | R1(config)#ip access-list standard acl-name |
Show
1 | // Shows all ACLs |
Another way to configure numbered ACL (in named ACL config mode)
Works similarly to named ACL; advantage is ability to delete rules by number.
Also, global config ACL deletion will delete the entire ACL, not individual entries.
1 | R1(config)#ip access-list standard NUMBER |
Resequencing ACL
1 | R1(config)#ip access-list resequence acl-id start-seq-num increment |
For example, ACL 1 may be numbered 1,2,3,4,5. If we wanted to insert a rule in-between, there are no integers left.
Resequencing as follows like such ip access-list resequence 1 10 10 changes the first entry to 10, and increments 10 after–resulting in 10,20,30,40,50. Now, we can add a rule in-between.
Extended ACL
number range: 100-199, 2000-2699
1 | R1(config)#access-list number [permit | deny] protocol src-ip dest-ip |
Extended Named ACL
1 | R1(config)#access-list extended {name | number} |
Specifying Port Ranges
1 | R1(config-ext-nacl)#deny tcp src-ip [eq | gt | lt | neq | range num num2] src-port-num dest-ip [eq | gt | lt | neq | range num num2] dst-port-num |
Show
1 | R1#show ip interface INTERFACE-ID |
CDP and LLDP
Enables neighbors to share information directly with each other.
CDP
1 | //Shows basic information about CDP (timers, version) |
LLDP
LLDP Configurations
1 | //LLDP is globally disabled by default. Enable globally deault |
show commands
1 | //Shows LLDP configuration information |
NTP
1 | //Default timezone is UTC |
NTP Configuration, Syncing to Google’s Time
1 | nslookup time.google.com |
Configure NTP servers to connect
1 | R1(config)#ntp server 216.239.35.0 |
NTP Configuration to a LAN device; R1 acts as a server for R2
Configure R1 first
1 | //Set R1's loopback interface (not required, but good practice) |
R2 is as follows:
1 | R1(config)#ntp server 10.1.1.1 |
NTP Configuration even when there is no external server; Set peers.
1 | // Uses default stratum level of 8 // will configure a loopback addresses (127.x.x.x) |
1 | //ConfigureNTP symmetric active mode |
1 | R3(config)#ntp peer IP-ADDRESS-OF-R2 |
NTP Authentication
1 | //Enable NTP auth |
1 | R1(config)#ntp authenticate |
1 | !Basic Configuration Commands |
DNS
Window DNS Commands
1 | ipconfig /all |
Configuring R1 as a DNS server -and- client
1 | //Configures router to act as a DNS server |
1 | R1#show hosts |
Set the domain name
1 | //e.g., ping pc1 => ping pc1.NAME.COM |
DHCP
1 | ipconfig /release |
DHCP Sever Configuration in IOS
1 | //Specify a range of addresses that won't be given to DHCP clients |
Show Configurations
1 | R1#show ip dhcp binding |
DHCP Replay Agent Configuration
1 | //Configure the interface connected to the subnet of the client devices |
DHCP Client (Use of DHCP to Configure the IP address of its interfaces); rare
1 | //Choose the interface |

SNMPv2c Configurations (N)
1 | //Optional Information |
Syslog (N)
Enable logging on different systems
1 | //configure logging into the console line (can use number or keyword (informational)) -- enables for gt 6 |
QOL Configurations
1 | //prevents logs from truncating current typing |
Service timestamps/Service sequence numbers
1 | //Configure and enable the timestamp |
SSH, Console Line, Telnet
Console Port Security - login
1 | R1(config)#line console 0 |
Console Port Security - login local
1 | R1(config)#username NAME secret PASSWORD |
Log the user out after X amount of inactivity
1 | line con 0 |
Layer 2 Switch - IP management

Assign an IP address to an SVI to allow remote connections to the CLI of the switch.
Recall switches do not have a routing table, and are not routing IP aware.
1 | SW1(config)#interface vlan1 |
Telnet Configuration
1 | //Required for telnet |
SSH
Check SSH Support
1 | // check ios image name for K9; NPE ISO images to countries with encryption restrictions |
Generate RSA Keys
- Must configure router host name and domain name.
1
2
3
4
5
6
7//First, configure the domain name has RSA keys require the FQDN (host + domain) to generate
SW1(config)#ip domain name EXAMPLE.COM
//Generate key (will be SW1.EXAMPLE.COM), choose size of the key (2048)
SW1(config)#crypto key generate rsa
//cryto key generate rsa modulus LENGTH // alternative
Configure SSH
1 | //Configure secret, username, and ACL (optional) |
Connect via SSH
1 | ssh -l USERNAME IP-ADDRESS |
FTP and TFTP
TFTP: Upgrading Cisco ISO
1 | //Check version, see crytographic support, etc |
FTP: Copying Files
1 | //Configure username and password R1 will use when connecting to FTP server |
NAT
Static Nat
Static NATs are a 1 to 1 mapping.
1 | //Define the 'inside' interface(s) connected to the internal network |
1 | //Show NAT translations |
Dynamic NAT Configuration
Configure Dynamic NAT
1 | //Define the 'inside' interface(s) connected to the internal network |
PAT (NAT Overload)
Configure PAT (almost same as Dynamic NAT with 1 difference: overload)
1 | //Define the 'inside' interface(s) connected to the internal network |
More common way to configure PAT
1 | //Define the 'inside' interface(s) connected to the internal network |
QoS | PoE and VoIP

IP Phones / Voice VLAN to Enable
1 | SW1(config)#int g0/0 |
Power Policing for PSE to PD Devices
1 | //default settings: disable the port and send a Syslog if a PD draws too much power |
QoS (N)
Identify the special type of traffic for QoS.
1 | //Create a class map |
Show commands
1 | //Class maps currently are "match-all" because we defined our our type. We can use 'match-all' or 'match-any' as needed |
Specify the treatment for traffic
1 | //policy-map NAMED is applied to an interface |
Port Security: Layer 2 (DHCP snooping, dynamic ARP inspection, port)
Port Security

Enabling Port Security
1 | //By default, most SW interfaces are 'dynamic auto'; need to configure to `mode {access | trunk}` |
Re-enabling a Secure-down status / err-disabled
1 | SW1(config)#int g0/1 |
Allowing automatic re-enable of Err-Disabled State (ErrDisable Recovery)
1 | SW#show errdisable recovery |
Violation Modes for Unauthorized MAC address (Port-Security)
- Shutdown: err-disables interface; 1 syslog
- Restrict: discards all traffic from unauthorized MAC address; syslogs per traffic
- Protect: discards all traffic from unauthorized MAC address; no syslog
1
2
3
4
5SW1(config-if)#switchport port-security
//manually configure MAC address
SW1(config-if)#switchport port-security mac-address MAC-ADDRESS
//Enable restrict mode
SW1(config-if)#switchport port-security violation {shutdown | restrict | protect}
Secure MAC Address Aging
- By default, secure MAC addresses will not age out: (Aging Time: 0 minutes);
- Absolute: MAC address is removed after timer expires, but can be immediately relearned on a new frame
- Inactivity: aging timer is reset every time a frame from the source MAC address is received
1
SW1(config-if)#switchport port-security aging type {absolute | inactivity}
Static secure MAC addresses can be made to age out as follows:
1 | SW1(config-if)#switchport port-security aging static |
Show command
1 | SW1#show port-security |
Sticky Secure MAC Addresses
1 | //Dynamically learned secure MAC addresses will be converted to 'sticky secure' and added to the running-config |
DHCP Snooping
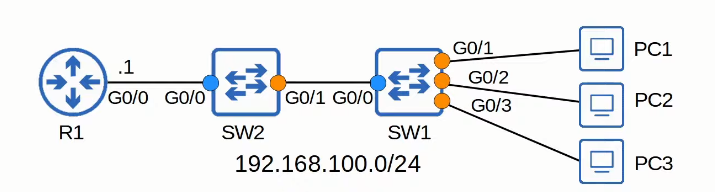
Messages from a DHCP server (OFFER, ACK, NAK) are discarded.
In untrusted interfaces, messages from a DHCP client (DISCOVER or REQUEST messages) are forwarded only if the source MAC address in the Ethernet frame matches the CHADDR field within the DHCP message. (Source MAC Address (Ethernet) === CHADDR)
Messages from a DHCP client (RELEASE or DECLINE messages) are forwarded only if the source IP address in the packet matches the entry in the DHCP Snooping Binding Table for the receiving interface.
Enable DHCP Snooping
1 | //Enable DHCP Snooping globally; |
1 | //Enable DHCP Snooping globally; |
What is no ip dhcp information option?
- Option 82 is reserved for DHCP delay agents.
- By default, Cisco switches and routers will drop option 82 on untrusted ports (with DHCP Snooping). A switch’s default settings will add “Option 82”, so the following switch will drop the DISCOVER + OPTION 82 packet (if settings are default).
- The default options work well if the the switch is a layer 3 switch acting as a DHCP relay agent, which is not the case in the diagram.
Show command
CLIENT: RELEASE/DECLINE messages will be checked with the DHCP Snooping Bind table; IP address and interface ID needs to match
1 | SW1#show ip dhcp snooping binding |
DHCP Snooping Rate - Limiting
1 | SW1(config)#int range g0/1 - 3 |
Dynamic ARP Inspection (DAI)
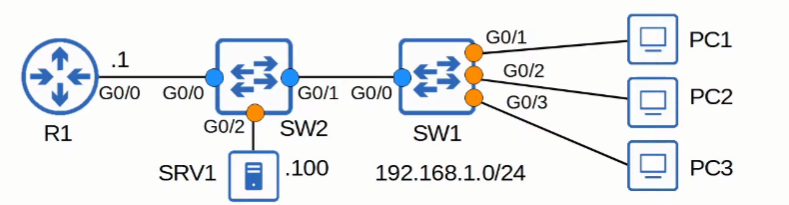
Enable DAI
1 | //Enable DAI on specific VLAN(s) |
1 | //Same configurations for SW1, with respective trusted ports |
View Trust State, Rate, and Burst Intervals of each interface, configure errdisable actions
1 | SW1#show ip arp inspection interfaces |
DAI Optional Checks
Default: DAI checks sender MAC and and IP addresses for matching entry in DHCP snooping binding table
1 | //Additional Checks for DAI |
ARP ACLs (N)
1 | //Static addresses do not have an entry in the dhcp snooping binding table. |
HSRP
1 | //Enter a VLAN first |
VRF-lite (N)
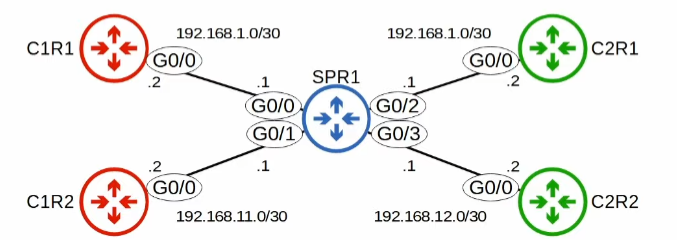
Without the use of VRF, two interfaces on the same router cannot be in the same subnet
1 | SPR1(config)# interface g0/0 |
With VRF
Create VRF
- Create VRFS:
ip vrf NAME - Assign interfaces to VRFs:
ip vrf forwarding NAME1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25SPR1(config)#ip vrf CUSTOMER1
SPR1(config-vrf)#ip vrf CUSTOMER2
SPR1(config-vrf)# do show ip vrf
SPR1(config-vrf)# interface g0/0
SPR1(config-if)# ip vrf forwarding CUSTOMERS
//VRFs remove IP-addresses already configured; so re-configure as needed
% Interface GigabitEthernet0/0 IPv4 disabled and address(es) removed due to enabling VRF CUSTOMER1
SPR1(config-if)# ip address 192.168.1.1 255.255.255.252
SPR1(config-if)# interface g0/1
SPR1(config-if)# ip vrf forwarding CUSTOMER1
% Interface GigabitEthernet0/1 IPv4 disabled and address(es) removed due to enabling VRF CUSTOMER1
SPR1(config-if)# ip address 192.168.11.1 255.255.255.252
//WORKS NOW--even if in the same subnet
SPR1(config-if)# interface g0/2
SPR1(config-if)# ip vrf forwarding CUSTOMER2
SPR1(config-if)# ip address 192.168.1.1 255.255.255.252
SPR1(config-if)# no shutdown
SPR1(config-if)# interface g0/3
SPR1(config-if)# ip vrf forwarding CUSTOMER2
SPR1(config-if)# ip address 192.168.12.1 255.255.255.252
SPR1(config-if)# no shutdown
Show command
Global routing table will not show VRF; fix as follows:
1 | show ip route vrf NAME |
Ping Commands
Normal pings follow the global routing table; fix as follows:
1 | ping vrf NAME IP-ADDRESS |